![]()

Efficient implementations of Needleman-Wunsch and other sequence alignment algorithms written in Rust with Python bindings via PyO3. Supports both binary match/mismatch scoring and custom pairwise scoring functions for applications like OCR text alignment, spatial matching, and other domains where continuous similarity measures are needed.
sequence_align is distributed via PyPi for Python 3.10 - 3.14, making installation as simple as the following --
no special setup required for cross-platform compatibility, Rust installation, etc.!
pip install sequence_alignAlternatively, if one wishes to develop for sequence_align, first ensure that both
Python and Rust
are installed on your system. Then, install Maturin and run
maturin develop (optionally with the -r flag to compile a release build, instead of an unoptimized debug build)
from the root of your cloned repo to build and install sequence_align in your active Python environment.
Pairwise sequence algorithms are available in sequence_align.pairwise.
The following algorithms are implemented:
- Needleman-Wunsch: Global sequence alignment with
O(M*N)time and space. - Needleman-Wunsch with custom scores: A variant that accepts a custom pairwise scoring function
score_fn(a, b) -> floatinstead of flat match/mismatch scores. This is useful when alignment quality depends on continuous similarity measures rather than binary element equality. - Hirschberg: A modification of Needleman-Wunsch with the same
O(M*N)time complexity but onlyO(min{M, N})space, making it an appealing option for memory-limited applications or extremely large sequences.
One may also compute the Needleman-Wunsch alignment score for alignments produced by any of the above algorithms
using alignment_score.
Using these algorithms is straightforward:
from sequence_align.pairwise import (
alignment_score,
hirschberg,
needleman_wunsch,
needleman_wunsch_with_scores,
)
# See https://en.wikipedia.org/wiki/Needleman%E2%80%93Wunsch_algorithm#/media/File:Needleman-Wunsch_pairwise_sequence_alignment.png
# Use Needleman-Wunsch default scores (match=1, mismatch=-1, indel=-1)
seq_a = ["G", "A", "T", "T", "A", "C", "A"]
seq_b = ["G", "C", "A", "T", "G", "C", "G"]
aligned_seq_a, aligned_seq_b = needleman_wunsch(
seq_a,
seq_b,
"_", # Represent gaps with this value
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
)
# Expects ["G", "_", "A", "T", "T", "A", "C", "A"]
print(aligned_seq_a)
# Expects ["G", "C", "A", "_", "T", "G", "C", "G"]
print(aligned_seq_b)
# Expects 0
score = alignment_score(
aligned_seq_a,
aligned_seq_b,
"_",
match_score=1.0,
mismatch_score=-1.0,
indel_score=-1.0,
)
print(score)
# See https://en.wikipedia.org/wiki/Hirschberg%27s_algorithm#Example
seq_a = ["A", "G", "T", "A", "C", "G", "C", "A"]
seq_b = ["T", "A", "T", "G", "C"]
aligned_seq_a, aligned_seq_b = hirschberg(
seq_a,
seq_b,
"_",
match_score=2.0,
mismatch_score=-1.0,
indel_score=-2.0,
)
# Expects ["A", "G", "T", "A", "C", "G", "C", "A"]
print(aligned_seq_a)
# Expects ["_", "_", "T", "A", "T", "G", "C", "_"]
print(aligned_seq_b)
# Expects 1
score = alignment_score(
aligned_seq_a,
aligned_seq_b,
"_",
match_score=2.0,
mismatch_score=-1.0,
indel_score=-2.0,
)
print(score)
# Custom pairwise scoring: align words using character overlap similarity
words_a = ["hello", "world", "foo"]
words_b = ["hallo", "welt", "baz", "foo"]
def char_overlap_score(a: str, b: str) -> float:
"""Score based on character-level overlap between two words."""
if a == b:
return 2.0
shared = len(set(a) & set(b))
total = len(set(a) | set(b))
return (2.0 * shared / total) - 1.0 if total > 0 else -1.0
aligned_words_a, aligned_words_b = needleman_wunsch_with_scores(
words_a,
words_b,
"_",
score_fn=char_overlap_score,
indel_score=-1.0,
)
# Expects ["hello", "world", "_", "foo"]
print(aligned_words_a)
# Expects ["hallo", "welt", "baz", "foo"]
print(aligned_words_b)To set up a local development environment, ensure that both Python and Rust are installed, then:
maturin develop -r # build and install in the active Python environment
./scripts/test.sh # run tests via pytest
./scripts/lint.sh # run all linters (ruff, mypy, cargo fmt, cargo clippy)
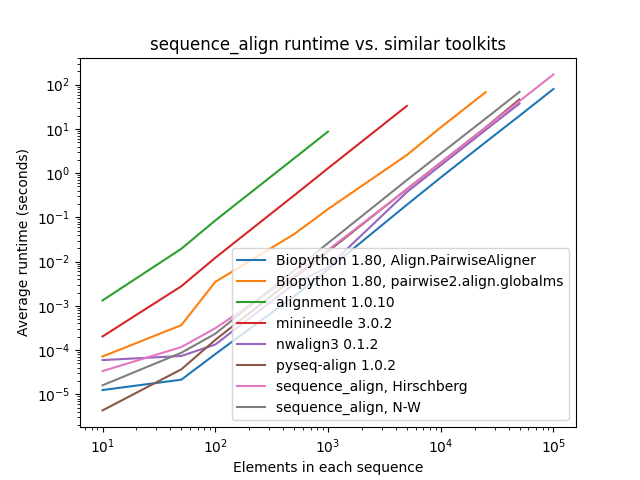
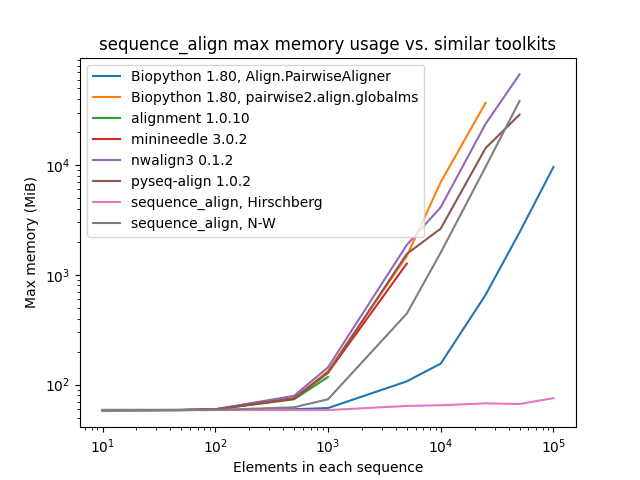
./scripts/lint.sh --fix # auto-fix where possibleAll tests below were conducted sequentially on a AWS R5.4 instance with 16 cores and 128 GB of memory. The pair of sequences for alignment consist of a character sequence of randomly selected A/C/G/T nucleotide bases along with another that is identical, except with 10% of the characters randomly perturbed by deletion, insertion of another randomly-selected character after the entry, or replacement with a different randomly-selected character.
As one can see, while sequence_align is comparable to some other toolkits in terms of speed, its memory performance
is best-in-class, even when compared to toolkits using the same algorithm, such as Needleman-Wunsch being used in
pyseq-align.
(Please note that some lines terminate early, as some toolkits took prohibitively long and/or ran out of memory at higher scales.)
See CHANGELOG.md for a full list of changes across versions.
Licensed under the Apache 2.0 License. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Copyright 2023-present Kensho Technologies, LLC. The present date is determined by the timestamp of the most recent commit in the repository.