Reorder calibration pipeline: clone before PUF, geography before QRF#516
Reorder calibration pipeline: clone before PUF, geography before QRF#516
Conversation
Recovered from JSONL agent transcripts after session crash lost uncommitted working tree. Files recovered: - calibration/national_matrix_builder.py: DB-driven matrix builder for national calibration - calibration/fit_national_weights.py: L0 national calibration using NationalMatrixBuilder - db/etl_all_targets.py: ETL for all legacy loss.py targets into calibration DB - datasets/cps/enhanced_cps.py.recovered: Enhanced CPS with use_db dual-path (not applied yet) - tests/test_calibration/: ~90 tests for builder and weight fitting These files need review against current main before integration. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Fixes identified by parallel review agents: 1. Wire up NationalMatrixBuilder in build_calibration_inputs() (was TODO stub) 2. Convert dense numpy matrix to scipy.sparse.csr_matrix for l0-python (l0-python calls .tocoo() which only exists on sparse matrices) 3. Add missing PERSON_LEVEL_VARIABLES and SPM_UNIT_VARIABLES constants 4. Add spm_unit_count to COUNT_VARIABLES 5. Fix test method name mismatches: - _query_all_targets -> _query_active_targets - _get_constraints -> _get_all_constraints 6. Fix zero-value target test to expect ValueError (builder filters zeros) 7. Fix SQLModel import bug in etl_all_targets.py main() 8. Add missing test_db/ directory with test_etl_all_targets.py 9. Export fit_national_weights from calibration __init__.py 10. Run black formatting on all files Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Replaces the legacy-only EnhancedCPS.generate() with a dual-path architecture controlled by use_db flag (defaults to False/legacy). Adds _generate_db() for DB-driven calibration via NationalMatrixBuilder and _generate_legacy() for the existing HardConcrete reweight() path. Also deduplicates bad_targets list and removes the .recovered file. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Make SparseMatrixBuilder inherit from BaseMatrixBuilder to eliminate duplicated code for __init__, _build_entity_relationship, _evaluate_constraints_entity_aware, and _get_stratum_constraints. Also remove the same duplicated methods from NationalMatrixBuilder (_build_entity_relationship, _evaluate_constraints, _get_stratum_constraints) and update all internal calls to use the base class method names. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Break the 1156-line monolithic ETL into focused modules: - etl_helpers.py: shared helpers (fmt, get_or_create_stratum, upsert_target) - etl_healthcare_spending.py: healthcare spending by age band (cat 4) - etl_spm_threshold.py: AGI by SPM threshold decile (cat 5) - etl_tax_expenditure.py: tax expenditure targets (cat 10) - etl_state_targets.py: state pop, real estate taxes, ACA, age, AGI (cats 9,11,12,14,15) - etl_misc_national.py: census age, EITC, SOI filers, neg market income, infant, net worth, Medicaid, SOI filing-status (cats 1,2,3,6,7,8,13,16) etl_all_targets.py is now a thin orchestrator that delegates to these modules and re-exports all extract functions for backward compatibility. All 39 existing tests pass unchanged. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Rename _evaluate_constraints → _evaluate_constraints_entity_aware in test_national_matrix_builder.py (4 tests) - Remove duplicate tax_unit_is_filer constraint from AGI stratum fixture (inherits from parent filer_stratum) (1 test) - Fix TestImports to use importlib.import_module to get the module, not the function re-exported from __init__.py (2 tests) - Fix reweight_l0 test patch path to policyengine_us.Microsimulation matching the actual import inside the method (1 test) - Add try/except fallback in build_calibration_inputs for when DB path fails, gracefully falling back to legacy build_loss_matrix (1 test) All 100 calibration tests + 39 ETL tests pass. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
State-level targets from independent data sources often don't sum to their corresponding national totals (e.g., state real_estate_taxes sums to only 17% of national). This causes contradictory signals for the calibration optimizer. Adds proportional rescaling: scale states to match national, then CDs to match corrected states. Original values preserved in new raw_value column for auditability. Validation step catches any future unreconciled targets. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Resolve conflict in enhanced_cps.py by keeping the db/legacy dispatch from this branch. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Drop reweight() (HardConcrete/torch), _generate_legacy(), use_db flag, and ReweightedCPS_2024 class. EnhancedCPS.generate() now always uses the DB-driven calibration via NationalMatrixBuilder + l0-python. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Delete utils/loss.py (build_loss_matrix, print_reweighting_diagnostics), utils/soi.py (pe_to_soi, get_soi), utils/l0.py (HardConcrete), utils/seed.py (set_seeds). Remove legacy fallback from fit_national_weights.py. Strip legacy tests from test_sparse_enhanced_cps.py. Delete paper/scripts/generate_validation_metrics.py and tests/test_reproducibility.py (both fully legacy). -2,172 lines. DB-driven calibration is the only path. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- NationalMatrixBuilder: add _classify_target_geo() and geo_level parameter to _query_active_targets() / build_matrix() for optional filtering by national/state/cd level - fit_national_weights: pass through geo_level param, add --geo-level CLI flag (default: all) - Tests: replace legacy build_loss_matrix mocks with NationalMatrixBuilder mocks, add test_passes_geo_level Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
New pipeline: clone extended CPS ~130x, assign random census blocks to each clone, build sparse matrix against all DB targets, run L0 calibration. Two L0 presets: "local" (1e-8, ~3-4M records) and "national" (1e-4, ~50K records). New modules: - clone_and_assign.py: population-weighted random block assignment - unified_matrix_builder.py: sparse matrix builder (state-by-state) - unified_calibration.py: CLI entry point with L0 presets 46 tests covering all modules. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Phase 1: simulate each clone, save sparse COO entries (row, col, val) to disk as .npz files. Resumable - skips already-completed clones. Phase 2: load all COO files and assemble CSR matrix in one pass. This keeps memory low during the expensive simulation phase (only one clone's data in memory at a time) and allows resume if the process is interrupted overnight. Also fixes l0_sweep.py call site to pass target_names and output_dir to the updated fit_one_l0 function. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Saves per-clone COO data to storage/calibration/clones/, enabling resume if the overnight sweep is interrupted. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The extended CPS h5 contains only input variables (or inputs with fallback formulas). Removed the blanket delete_arrays call that was clearing survey-reported values like employment_income. Only in_nyc needs clearing since it's geo-derived and stored in the h5 with a stale value from original CPS geography. Added test asserting no purely calculated variables exist in the h5, guarding against stale values leaking into calibration. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The extended CPS h5 should contain only true input variables. Removed all delete_arrays logic from _simulate_clone since there's nothing to clear. Added test asserting no PE formula variables are in the h5, with an explicit allowlist for known imputed/survey values. Currently xfail because in_nyc is present and needs to be removed from the dataset build process. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Full pipeline reorder incomingI'm restructuring the unified calibration pipeline to move PUF cloning after geography assignment, so each geographic clone gets its own state-informed PUF imputations via QRF. New pipeline:
Key benefits:
Updated pipeline comparison diagram attached below. |
Visual comparison of old national, old local area, and new unified calibration pipelines showing the restructured flow. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Updated pipeline diagram
I'm implementing the full pipeline reorder in this PR. The key changes:
|
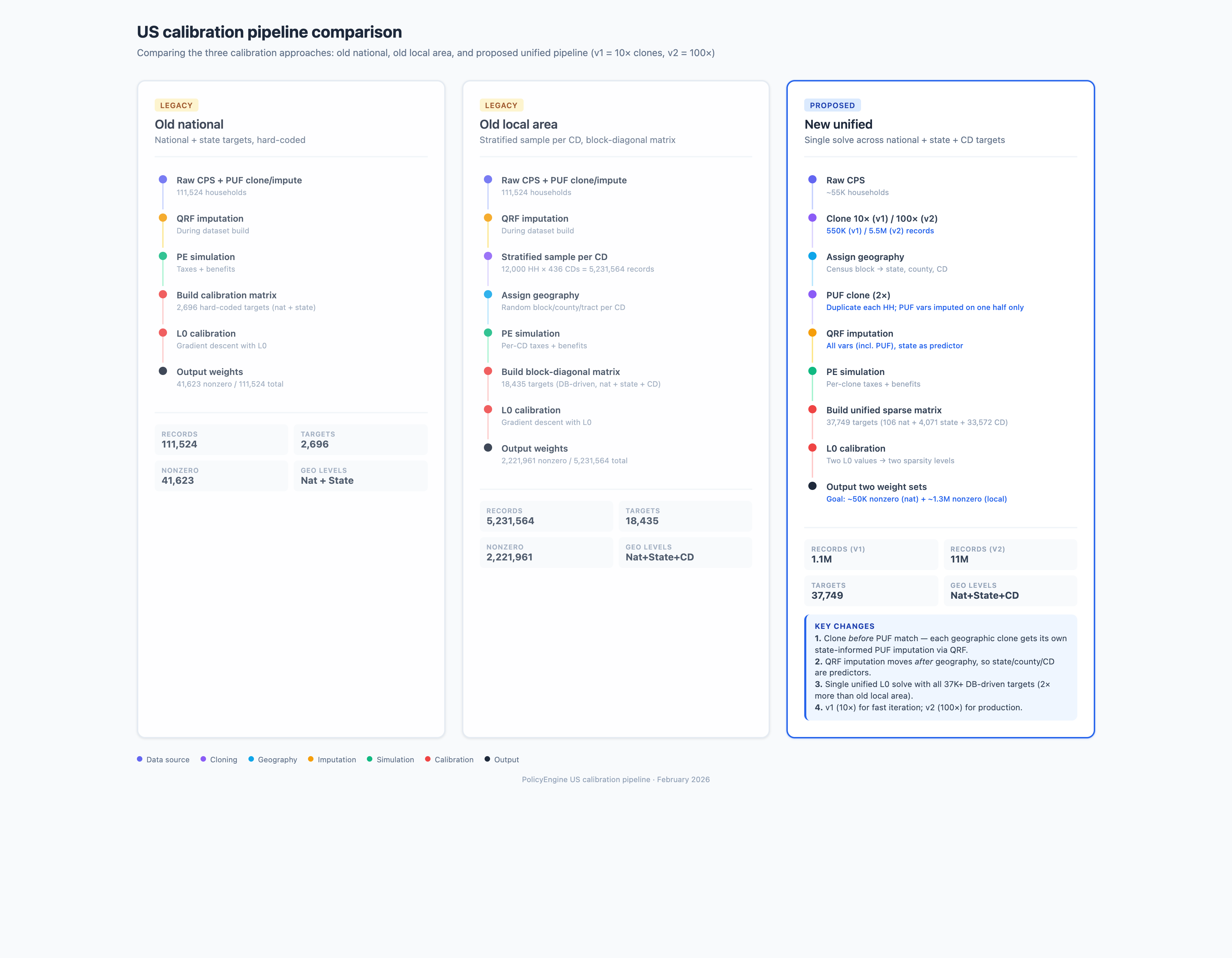
Restructure the calibration pipeline so that: 1. Raw CPS is cloned 10x (was 130x from ExtendedCPS) 2. Geography is assigned before PUF imputation 3. PUF clone (2x) happens after geography assignment 4. QRF imputation uses state_fips as a predictor New module: puf_impute.py extracts PUF clone + QRF logic from extended_cps.py with state as an additional predictor. New helper: double_geography_for_puf() doubles the geography assignment arrays to match the PUF-cloned record count. Default n_clones changed from 130 to 10 for fast iteration (v1). Production can use --n-clones 100. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…level Two bugs when running with real PUF data: 1. X_test was missing demographic predictors (is_male, tax_unit_is_joint, etc.) because they're computed variables not stored in the raw CPS h5. Fix: use Microsimulation to calculate them. 2. Imputed tax variables were stored at person-level length but many belong to tax_unit entity. Fix: use value_from_first_person() to map to correct entity level before saving, matching extended_cps.py's approach. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Removed subsample(10_000) on PUF sim and sample_size=5000 in _batch_qrf so QRF trains on all available PUF records. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Per the pipeline diagram, "QRF imputation: All vars (incl. PUF), state as predictor" — all imputations (not just PUF) should use state_fips as a predictor. This adds: - source_impute.py: Re-imputes ACS (rent, real_estate_taxes), SIPP (tip_income, bank/stock/bond_assets), and SCF (net_worth, auto_loan_balance/interest) with state_fips as QRF predictor - Integration into unified_calibration.py pipeline between geography assignment and PUF clone - --skip-source-impute CLI flag for testing - Tests for new module (11 tests) Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
count_under_18, count_under_6, is_female, is_married etc aren't PE variables — compute them from the data dict and raw arrays instead of requesting from Microsimulation. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…ntity SCF variables (net_worth, auto_loan_balance, auto_loan_interest) are household-level but QRF predicts at person level. Without aggregation, the h5 file gets person-length arrays for household variables, causing ValueError when Microsimulation loads the dataset. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The legacy ETL scripts (etl_misc_national, etl_healthcare_spending, etl_spm_threshold, etl_tax_expenditure, etl_state_targets) existed but had never been run against the production database. This commit: - Fixes a bug in etl_misc_national.py: the SOI filing-status constraint used 'total_income_tax' which doesn't exist in PolicyEngine US; changed to 'income_tax'. - Runs load_all_targets() to populate the DB with 2,579 additional targets for period 2024, bringing the total from 9,460 to 12,039. New target categories added to the DB: - 86 Census single-year age populations (ages 0-85) - 8 EITC by child count (4 buckets x returns + spending) - 7 SOI filer counts by AGI band - 36 healthcare spending by age (9 bands x 4 expense types) - 20 SPM threshold deciles (10 x AGI + count) - 2 negative household market income (total + count) - 5 tax expenditure targets (reform_id=1) - 289 SOI filing-status x AGI bin targets - 104 state population (total + under-5) - 51 state real estate taxes - 102 state ACA (spending + enrollment) - 51 state Medicaid enrollment - 900 state 10yr age targets - 918 state AGI targets Adds test_legacy_targets_in_production_db.py with 17 tests verifying all legacy target categories are present in the DB. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Force line-buffered stdout and monkey-patch print() for nohup flush - Log to stderr to avoid stdout buffering issues - Auto-save unified_diagnostics.csv and unified_run_config.json - Add phase timing (geography, matrix build, optimization, total) - Add compute_diagnostics() for per-target error analysis - Add --stratum-groups CLI flag for selective target calibration - Add calibrate_only and stratum_group_ids filters to matrix builder - run_calibration() returns (weights, targets_df, X_sparse, target_names) Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Without this, logging.basicConfig(stream=sys.stderr) output was block-buffered when redirected to a file, making clone progress invisible until buffer flush. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Lambda sweep results (directional — needs PUF re-run)Ran a lambda_l0 sweep on v1 (10 clones × 55K HH = 558K records, 100 epochs each). Caveat: these runs used Sweep results (v1, 100 epochs, no PUF)
Key finding: sparsity is freeMean error is ~60-61% across all lambdas. Pruning 90% of weights doesn't hurt fit quality at 100 epochs. This makes sense — with 558K weights fitting 40K targets, most weights are redundant. The original run used Extrapolation to diagram targetsPer the pipeline diagram, we want two weight sets:
What didn't work
Next steps for @baogorek
Full sweep log at |
Port core census-block architecture from Max Ghenis's PR #516 onto current main. New calibration/ package with: - clone_and_assign: population-weighted census block sampling - unified_matrix_builder: clone-by-clone simulation with COO caching, target_overview-based querying, hierarchical uprating - unified_calibration: L0 optimization pipeline with takeup re-randomization Remove old SparseMatrixBuilder/MatrixTracer/fit_calibration_weights and their associated tests. Simplify conftest.py for remaining tests. Co-Authored-By: Max Ghenis <max@policyengine.org> Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…530) Adds puf_impute.py and source_impute.py from PR #516 (by @MaxGhenis), refactors extended_cps.py to delegate to the new modules, and integrates both into the unified calibration pipeline. The core fix removes the subsample(10_000) call that dropped high-income PUF records before QRF training, which caused a hard AGI ceiling at ~$6.26M after uprating. Co-Authored-By: Max Ghenis <mghenis@gmail.com> Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Add census-block-first calibration pipeline (from PR #516)
…530) Adds puf_impute.py and source_impute.py from PR #516 (by @MaxGhenis), refactors extended_cps.py to delegate to the new modules, and integrates both into the unified calibration pipeline. The core fix removes the subsample(10_000) call that dropped high-income PUF records before QRF training, which caused a hard AGI ceiling at ~$6.26M after uprating. Co-Authored-By: Max Ghenis <mghenis@gmail.com> Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Summary
Restructures the unified calibration pipeline so geography is assigned before PUF imputation, enabling state FIPS to be used as a QRF predictor. This improves state-level accuracy of imputed tax variables.
New pipeline flow
Key changes
puf_impute.py: Extracts PUF clone + QRF imputation fromextended_cps.pyinto a standalone module.DEMOGRAPHIC_PREDICTORSnow includesstate_fips.clone_and_assign.py: Defaultn_clonesreduced from 130 to 10 (fewer clones × more records per clone after PUF doubling). Addeddouble_geography_for_puf()helper to duplicate geography arrays when PUF cloning doubles records.unified_calibration.py: Rewritten to implement the new pipeline order. New CLI flags--puf-datasetand--skip-puf. Default input changed fromextended_cps_2024.h5tocps_2024_full.h5(raw CPS before any PUF processing).docs/pipeline-comparison.png.Testing
puf_impute.py(clone logic withskip_qrf=True)double_geography_for_puf()--skip-puf --n-clones 2 --epochs 3on real CPS data (55K HH, 37K targets, ~2 min)Test plan
--skip-pufpath works with real data🤖 Generated with Claude Code